

8月11日,由腾讯游戏学院举办的第二届腾讯游戏开发者大会(TGDC)在深圳举行。大会技术论坛中,腾讯互动娱乐游戏AI研究中心总监邓大付带来了《牌类游戏的AI机器人研究初探》的主题演讲。演讲中,邓大付和大家分享了牌类游戏AI的研发经验,讲解了如何将AI强度提升至人类高级玩家水平,甚至和人类玩家进行局内配合。

以下是演讲实录:

我的分享分为三个部分,首先会简单地介绍我们所处理的问题和背景,然后会讲述如何用深度学习的技术做基本的AI,它的水平到底是什么样子?最后分享用深度学习做出来的AI有哪些问题,我们如何解决这些问题。
问题概述
在讲为什么要做斗地主的AI之前,分享一个小故事。我本人也喜欢玩斗地主,无聊的时候斗一两把。有一次躺在沙发上斗地主,我老婆在厨房做饭,我正好拿了一把好牌,一对鬼,一对2,还有一个炸弹,想着这把可以多赢一点。但刚抢到地主的时候,我老婆在厨房叫我“大付,你赶快给我买点葱,等着葱下锅”。没办法,家里领导有令,就马上把APP收起来,到楼下超市去买葱。等回来再把斗地主的APP打开的时候,发现没有赢8倍,反而输了8倍。
大家知道,在斗地主里面,有一个托管AI,你离开游戏的时候,AI会自动接管。当时心里很不爽。后来跟做斗地主项目的同学一起聊,能不能把AI的水平提高一点。项目组的同事跟我们说,现在基于规则的方法已经很难对它进行提高了。反过来跟我说,你不是做机器学习的吗?能不能帮我们做一个AI,这个AI满足以下三个条件就可以:
第一,智能水平要有一定的高度,比如说要跟人类的高手差不多。当然不需要像AIpha GO那样强,可以击败人类顶尖高手。因为击败人类的顶尖高手,对游戏本身来说也没有特别大的意义。
第二,行为要特别像人,在托管的时候为了让其他玩家感觉不出来,必须要把整个行为模式做地特别像人。
第三,AI的运营成本不能太高。大家知道,斗地主是有上千万的用户,如果说我们做的太复杂,后台的运营成本是受不了的。
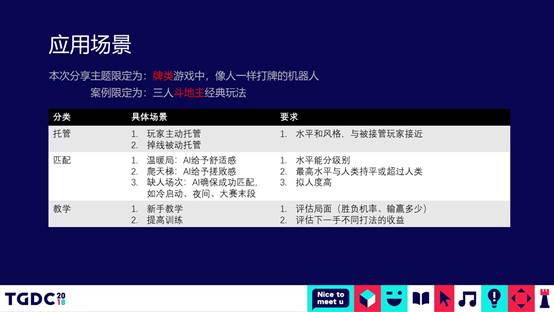
如果能做出来,我们这里就会有很多应用场景。
第一,在做托管的时候;第二,做匹配的时候。因为是竞技类的游戏,玩家之间会相互匹配,有的时候运气不好,会匹配到一些水平比较高的对手,跟他玩的话输的概率会比较大。假设这个时候要匹配一些水平比较低的人,水平比较低的人心情也不爽。这个时候如果有一个水平差不多的一起玩,用户的体验会更好一些。
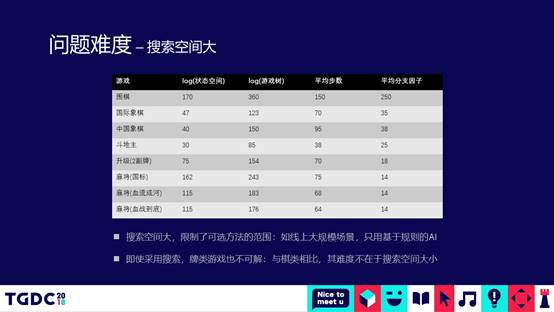
当然,还有其他很多应用场景,我们拿到这个项目之后做了一个调研,想看一下这个问题到底有多难。简单地看一下,所有的棋牌类游戏,包括围棋、中国象棋、斗地主、麻将等,状态空间都非常大。以围棋为例子,有人做过这样形象的比喻,围棋盘面的复杂度相当于太阳系的原子个数那么多。斗地主虽然比围棋要小一些,但是估计也跟整个深圳市所包含的原子数目差不多。依照牌面进行穷举来做出高智能的AI实际上是不太可能的。
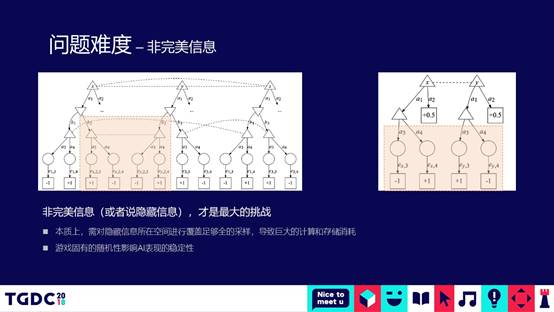
当然了,从这个对比过程中我们可以看到,斗地主盘面的复杂度是10的30次方,围棋是10的170次方,AIpha zero基本上所有的棋类困局基本上都已经解决了,我们是不是使用AIpha zero的技术,是不是可以达到项目组想要的目的?实际上问题并没有那么简单。对于棋类的游戏,牌面所有的信息都是双方可以互见的。但是对于斗地主来说,一方是看不到其他两方牌,这个时候实际上我们就要对其他两方牌做各种不同的组合。这种组合之后,会使盘面的复杂度再度地进行指数级的爆增,学术界把这个叫非完美信息的博弈问题。

对于这种非完美信息的博弈问题,学术界也有一些研究,最有名的是DeepStack和冷扑大师。DeepStack跟AIpha GO的整体思想很像,提出了基于把所有组合进行可能性的扩展之后,寻找博弈上的纳什均衡点的方式来解决。冷扑大师相对来说会聪明一些,会把整个盘面分为开局、中局、残局,分别用不同的方法解决这里面的问题。去年冷扑大师的作者过来腾讯跟我们进行交流,他给我们透露一个信息,2017年年初的时候,冷扑大师在国际德州扑克进行大师赛的时候,第一次机器人在非完美信息博弈上胜过人类的顶级大师,后台接的是CMU的超级计算机,进行在线的推导。如果说用这种方式来做,要面对腾讯上千万级别的用户,实际是不太可能的。

有没有其他的方法呢?对于工业界来说,因为斗地主在线上运营的时间比较久,我们有海量的用户数据。我们后台有比较多的CPU和GPU可以处理留下的海量数据。我们的第一个方法,看能不能通过监督学习,现在学术界换了一个名字,因为是模仿人类的动作,取了一个名字叫模仿学习,用模仿学习的方法解决斗地主牌类的问题。
基本AI的构建

下面这部分给大家大致的介绍一下我们是如何一步步构建斗地主的基本AI的。最原始的想法,从人类的数据中直接学人的行为,人在牌面的时候该怎么动,机器人就跟着去学。
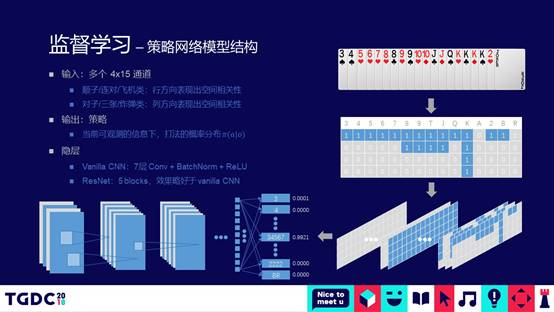
对于牌类的问题,实际上有一个比较好的模型,通过CNN进行分类。为什么要通过CNN来做呢?因为CNN有一个特性,这个特性最开始主要是针对图片的处理,对空间特征进行提取的能力和效率会比较高一些。
对于牌类游戏来说,我们可以把CNN的通道排成15个横牌,竖牌4个的矩阵,横排分别表现3456789,一直到小鬼和大鬼,竖牌表示不同的花色。这样CNN就可以通过卷积编码出斗地主规则的顺子、对或3带2的空间特征。这个模型的输出,直接就是进行什么样的动作。斗地主的动作空间会很大,大概有13350多种,围棋的盘面,每一步下子的可能性是361种,斗地主会有一万多,因为斗地主有不同的组合。
有了这个基础的模型,我们可以做第一步的初步训练,初步训练的效果不是特别理想,包括分类的准确度和AUC都不是特别理想,因此我们对整个模型做了一下三个优化。
下面主要给大家介绍一下三个优化。
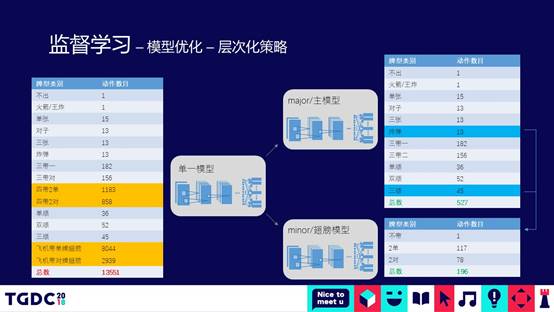
第一种优化,对模型的输出做了比较大的梳理和优化,从左表可以看出斗地主出牌的可能动作空间,可以看到13551种动作当中,大部分集中在4带2或是飞机带,因为可以带两张,各种组合数据特别多。我们就把原始单一的模型拆成一个层次化的模型。有什么好处呢?在第一层把4带2或飞机带拆到第二层的模型去做。第一层只是识别可不可能存在这种情况,如果存在放在第二层模型再做预测和分类。这样的话,整个模型跟飞机带和4带2比较像,像翅膀一样,所以我们把这个模型叫层次化的翅膀模型。在第二层模型的时候,整个组合数就会变得比较小。只有百的级别。这就象人进行分类的时候一样,假设100多个种类的东西放在你面前,你可以比较清楚的识别出来,但是1万多个东西放在你面前,你可能就会认错。
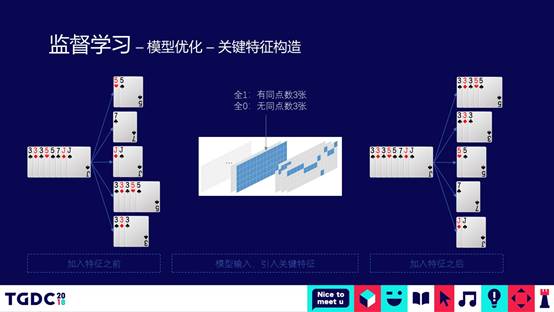
第二种优化,我们人工地做了一些关键特征。在机器学习领域,深度学习出来的时候,很多做机器学习的人都说以后解放了,不要再做人工的特征提取。从我们自己实战的结果来看,人工做一些抽象的特征总结和提取,对模型整体的精度还是有比较大的好处。这里举了一个例子,左边的排是3个3,一对5,一个7,一对J。从这个牌里面提取特征,提取出来的特征意义是,这副牌有没有三个的,如果有三个的在CNN的通道加一层赋予全1,如果没有就是全0。
左边后面的排序是没有加特征抽象之前的排序结果,会先出一对5,再出一个7,概率最大的是先出一对5。加了有通道的结果,3个3带一对5,分类排序的时候可以得到更大的概率值。
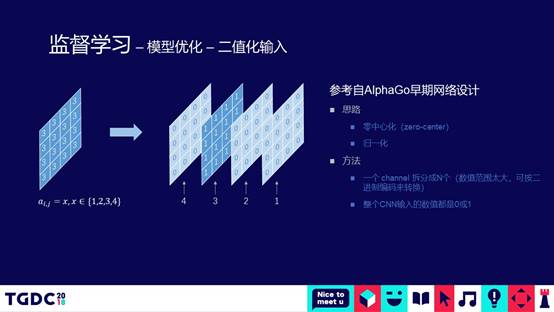
第三种优化,是在做CNN分类通常都会做的,二值化的处理。假设有一个特征值,取值范围是1234。这个时候取了3,实际上在整个CNN通道有两种表示方法,第一种表示方法是只用一个通道,上面附一个值是3;第二种表示方法是4个通道,在第三个通道上赋全1表示这个值的取值是3,对做卷积操作来说,二值化的处理通常会取得比较好的结果。
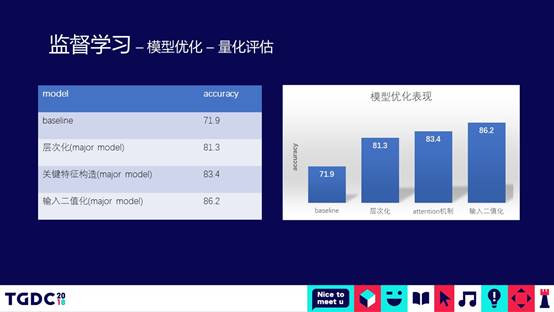
经过了三种方法的优化,整体模型的精度有了较大的提升。由于第一层优化做层次化之后,直接提升了大约10%左右。第二个和第三个优化也给整个模型的精度大概提升了5%左右。模型的精度达到86%左右的时候做了第一次大规模的训练。高倍场的玩家水平通常更高,我们随机从高倍场的比赛中抽了400万局的对局出来。如果是一个人去玩斗地主的话,不吃不喝不睡估计要打8-10年才能达到400万局的规模。我们用了两块GPU的卡联合一起训练,对400万局的数据用这个模型来训练。大概用了8个小时左右的时间,模型收敛到比较好的状况,我们用一个例子看一下模型到底到什么样的水平。
这个例子中,地主的牌非常好,有两个大鬼,一对2,还有一个7炸。第一手牌出了6,因为有7炸,假设拆了的话就会有3456789 10的顺子全部变成单牌。出6的话有倾向把7炸拆掉,而不是说把7炸留着单张打。从这点来看,这个AI实际上已经学到了人类在打牌的时候,有从整体盘面的局势进行规划和长远考虑的趋势。
从农民二出的一对4,以及地主的一对7,农民二用2拿到了发牌权,这个时候为什么出了一对4呢?人在打牌的时候经常也会这样,地主首先出单牌,农民二认为地主的对或三个的会比较弱,农民二学会了人在打牌的时候攻击对手弱点的策略。当地主看到一对4的时候,毫不犹豫把7炸拆了,贯彻之前规划的打法。
农民一通过一对9接到这手牌,因为他在地主的下家,需要给地主压力,尽可能的跑,人打牌的时候也会这样,压迫感的打法,使地主发慌,才可以从中谋取胜机。拿到牌之后,先出了3个J带,接着把3个K的飞机直接打出去,迫使地主要用一对鬼来炸。后面通过快进的方式看这一局,最后的结果,这两个农民通过一些精巧的配合,最终打胜了地主一副很好的牌。

我们对监督学习的整体效果做一个总结,当然中间还有很多其他类似的经典案例。从这里面来看,我们有了一个非常令人惊喜的结果,直观上看整个对战,AI智能体的打法跟人几乎区别不出来。我们自己在看的时候,每一步出牌的过程好像是经过了思考一样。从实际线上测试的数据来看,跟人进行随机匹配的时候,对战的胜率超过人类选手的平均水平。
AI的强化

事情是不是就这么结束了呢?通过一个模仿学习的方法,通过三个阶段的优化就能够很好地完成AI,实际上并没有这么简单。它也有表现不好的一面,我们通过大量的观察发现一些问题,这些问题尤其是在局末的时候表现的特别突出,两个农民的配合偶尔会出现失误。下面的部分,主要给大家讲一下都是些什么失误,为什么会产生这些失误?以及我们如何解决这些失误。
举个例子,到局末的时候,地主只剩下一对A,这个时候对于农民二来说,分类器排名第一的是出一对6,排名第二是正确的打法,排名第一的打法是错误的。因为这个概率排出来是一对6最大,农民二毫不犹豫把一对6出去了,导致可以把地主打败的牌失败。为什么会出现这种现象呢?我们经过仔细分析发现,前面400万局是从人类选手实际打牌的过程中提取出来的出牌过程。因为人都会犯错,就会引入很多人类所犯过的错误。通过前面的模仿学习或监督学习的原理,实际上机器人并不明白斗地主到底是怎么一回事,只是在模仿人类在不同盘面下怎么出牌的动作,或者说模仿人类在不同盘面下动作的概率分布。
AI不仅学会了人好的一方面,像人能够抽象出来的一些战略性的思想方面的东西,而且学会了人类犯的错误。有时候这些低级的错误,比如说农民二,假设AI在线上在这种情况下出了一对6,另外一个农民是人的话,他就会觉得很不爽,觉得太傻了。
我们如何解决呢?因为这个问题的本质是来自于数据的样本,当然我们做机器学习的同学可能会说,可以通过人工的方法把400万局过滤一遍,把错误的样本剔出去。正所谓人工智能全靠“人工”,传统的方法确实这么做。对于我们来说,我们感觉代价有点大,第一次大规模的训练只用了400万局,未来的训练想用2000万或上亿级的数量来训练AI,人不可能把样本过一遍。
我们用什么方法来处理呢?大家想一下人怎么玩斗地主这个游戏。高手在打斗地主的时候,通常都会根据其他的人已经出过的牌来猜对手手上可能还有什么牌,因为记得住每个人打过什么牌,来猜对手手上还有什么牌。通过猜出来其他人剩下的牌,结合自己手上的牌面制定打牌的策略。猜的人准确率越高,记牌的能力越强,这个人打牌的水平就会越高。

基于这点思考,我们就想可不可以做一个猜牌模型。当然,因为我们前面发现的错误案例主要集中在局末。为了使猜牌变得简单,我们做了一个简单的假设,当有一个人听牌的时候(手上牌的数目小于等于2)开始猜牌,原始深度模型的学习输入跟翅膀模型是一样的。输出变了,先猜还有两张牌那个人手上的牌。总共有134种组合,假设有一张单的时候,有14种,假设有两张,出现一对有14钟,两张单的各种组合105种,然后重新构造样本来做猜牌模型。
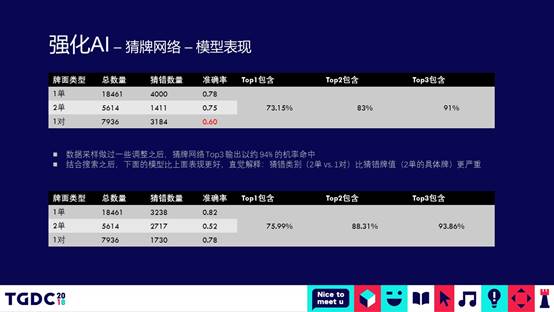
我们做了两组不同的采样,第一组跟第二组相比,相对来说第一组在两张单的时候准确率会更高一些,第二组猜对牌型的准确率更高一些。对于Top3的概率来看,Top3命中的准确率可以达到93.86%,接近94%。两种模型相比较,第二种模型整体表现会更好一些,可能是因为:斗地主在局末的时候,猜对牌型比猜对牌是什么值会更重要一些。
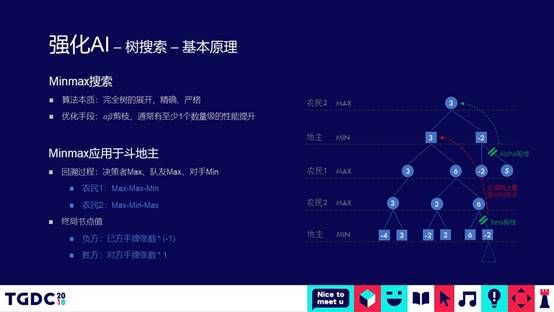
有了这么准的猜牌模型,接下来就可以把前面所说的非完美信息的问题转化成完美信息,就跟下棋一样,已经大概知道别人的牌是什么样的,然后就可以进行推理。用什么样的推理方法呢?棋类有各种各样进行搜索的方法,AIpha GO用的MCTS,我们用Minmax的搜索方法,这种方法实际上是在博弈论里面更古老的算法,有一个经典的案例应用是在1997年的时候“深蓝”打败卡斯帕罗夫,算法原理很简单,就是暴力的搜索,把所有的可能性搜出来。
因为是暴力完备的搜索,就会导致很慢。即使只剩下两张牌,盘面的情况,如果不做任何优化的Minmax搜索大概要运行几十分钟,后面每走一步都要进行一次搜索,这对我们来说基本上是不可行的。必须要对这个东西进行优化。怎么优化呢?

我们做了三种优化手段,第一种比较简单,实际上是一种检值的算法,当在进行搜索的过程,一旦发现某一个分支下面有必胜的路径,这个时候马上停止搜索进行返回。就好像孙悟空到海里找宝一样,已经找到最好的宝就不要再找了。这种方法使用上之后,Fast pruning,这个方法对性能提升了1000倍。
第二种方法是Caching,跟人打牌的过程中,到最后只剩下两张牌的时候有大量的牌型是重合的,把之前搜过的解法直接Caching,就可以不用搜了。这个优化又给我们提升了100倍的速度空间。
第三步的优化,Minmax搜索的过程是从左到右,进行深度搜索的过程。在每一层进行深度搜索的过程,我们可以把每一层上面的节点进行排序,其实比较简单。我们也可以用模型来排序,也可以用一些简单的规则,比如说尽量出多的打法,或者是用模型,人类最有可能打的打法排在前面。这样的话,最有可能找到前面的第一个,一定会胜的那个路径。总共乘起来,性能优化就会优化10的6次方,相当于6个量级的地步,意味着前面做推理的时候,拿单CPU的核要经过几十分钟进行推理的过程,缩短到毫秒级别,意味着几百万的用户可以用几十台机器完全支撑起来。
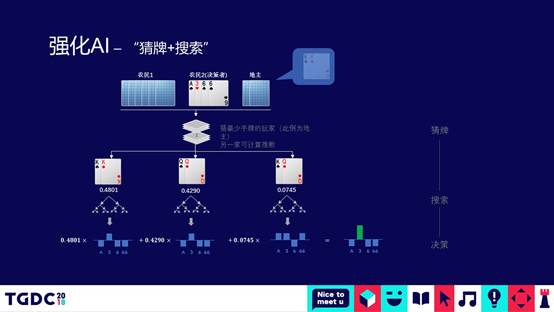
结合猜牌+搜索,到局末的时候怎么打。举个例子,这个地主还剩下一对K,农民二首先进行猜牌,通过猜牌模型猜地主手上有什么牌,猜到一对K的概率是0.48%,可能是一对Q的概率是0.42%,可能是K、Q组合的概率是0.074%,这个时候在三个分支上取Top3的分支进行搜索,进行搜索推理,发现在一对K的分支下应该先出3会赢,在一对Q下面也是先出3。在后面一个Q、K组合的概率下,先出A跟先出3,或者是先出6都可以赢,综合把三个分支的概率加权累加起来,就得出先出3一定是对的,所以先出一张3,把地主的一对K拆散。
经过在末局猜牌和推理的过程进行优化之后,我们来看一下优化前后的对比牌局,如果没有经过优化直接出一对5,地主一对K就走了。经过优化的情况,可以看到4的概率是100%,所以先出了4,地主出K,拆散了之后最后把地主打败了。

到了这个阶段之后,AI整个过程在牌的初始开局和中局的时候是模仿人的打法,到终局的时候用猜牌推理,就可以得到一个比较大的强化。到底得到多大的强呢?实际上我们可以看到以前在局末的配合失误基本上没有,一个都没有。为什么呢?从前面的测试数据也可以看到,猜牌模型在Top3的概率下,准确度能到94%。实际上打到最后的时候,AI已经接近于一个上帝视角的水准。
用这样的模式还有一个好处,初局的时候打法非常像人,如果一开始就用猜牌和搜索的方式,可能会打出不像人的打法,像AIpha GO跟人类选手下棋跟人类不一样的想法,我们在做产品的时候并不一定需要这个东西。
当然,这种方法相对于业界或学术界解决非完美信息的解决方法来说,有几个缺点:
第一,理论上实际上并不是特别完备的,大家可以看到,我们只处理了最后两张牌。当然了,再往上也可以处理3、4张,一直到17张的猜牌都可以做。
第二,这对于斗地主一个游戏进行独立优化的一种方法,是我们做产品或者说工业界的一种做法,相对于那“DeepStack”和“冷扑大师”两种方法,它有一个非常大的优势,制作过程相对会比较简单;性能高,高到什么地步呢?我们做过一个评估,大概50台服务器的成本就可以支撑所有用户使用AI场景的量,基本上每台机器每秒可以处理200次以上的请求,这是纯CPU的机器。如果用深度学习做处理的时候,很多人都用GPU。
我今天的分享就先到这里,谢谢大家!






