



一. 引言
游戏是一项非常重要的娱乐行业,是世界上最赚钱的行业之一。中国音数协游戏工委(GPC)、伽马数据(CNG)、国际数据公司(IDC)联合发布的《2018年中国游戏产业报告》中披露,2018年中国游戏行业整体收入为2144.4亿元,同比增长5.3%,占全球游戏市场比例约为23.6%,是世界第一大游戏市场。游戏产业发展的历史中,每次重大技术革新都会赋予游戏更多的内涵与改变。微型处理器的诞生,让电子游戏登上历史舞台,个人电脑的普及,开启了单机游戏的时代,互联网的兴起,则让网游在世界上流行起来,智能手机的普及,将我们带入了手游时代,而各种游戏引擎的出现和更新则提高了游戏开发的速度和质量。
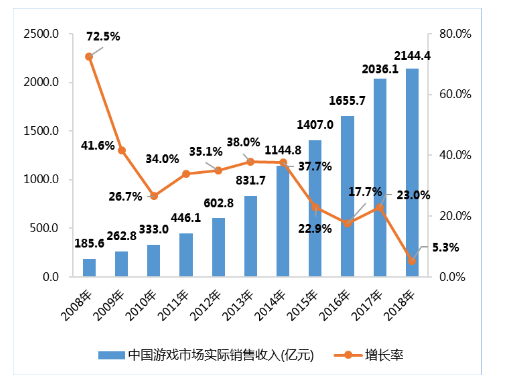
图1 中国游戏市场实际销售收入变化
一次次的技术更新或是创造了新设备,或是提供了新场景,或是提高了游戏开发的效率。如今的游戏产业中,仍然存在着一些痛点,比如游戏内机器人和NPC的研发流程繁琐且难以达到很好的效果,比如角色动画的开发流程非常复杂,比如游戏的测试流程和精细化运营流程存在改进的空间,在传统的游戏开发流程中,它们都需要大量有经验的研发人员进行支持,导致游戏研发成本居高不下。
另一方面,机器学习应该是近年来受到最广泛关注的技术之一。随着新的机器学习算法的提出及算力的提高,机器学习技术正在影响着诸如金融,安防,医疗等众多行业,提高了这些产业的生产效率。其中,以深度学习为代表的监督学习方法最广为人知,使用也最为广泛。深度学习主要通过大量的有标记样本来进行训练,基于深度模型的强大的表示学习的能力,在拥有大量有标记数据的场景下往往能够得到显著优越的效果。比如基于大量的有标记的动物图片进行训练,得到的模型就能够判断一张新图片是什么动物。
然而,在很多场景下有标记的样本很难获得,代价很大。以上面提到的研发游戏内的Bot和NPC为例,如果我们想用深度学习技术,就必须用大量的人类玩家在游戏内的操作数据来训练模型。这就意味着这种方法只在那些已经上线且记录了用户的大量操作数据的游戏中有实现的可能性,适用范围有限。角色动画等场景也存在着相似的问题,本身就不存在足够的数据来进行训练。
与深度学习不同的是,深度强化学习是让智能体在环境中进行探索来学习策略,不需要经过标记的样本,在近年来也受到广泛关注。基于深度强化学习,DeepMind研发的AlphaGo Zero在不使用任何人类围棋数据的前提下,在围棋上完全虐杀人类;OpenAI研发的Dota Five则在Dota游戏上达到了人类玩家的顶尖水平;DeepMind研发的AlphaStar在星际争霸游戏上同样击败了人类职业玩家。这些都成了深度强化学习发展的里程碑的事件,证明了深度强化学习在这些场景下的强大能力。

图2 AlphaGO在围棋上打败了李世石
当然,深度强化学习也存在一些问题,其中重要的一点就是其必须通过不断的试错,探索环境进行学习来寻找更好的策略。在金融,电商推荐等场景,一次错误的尝试可能意味着巨大的损失。但值得庆幸的是,游戏本身就是一个仿真的环境,探索成本很低。也就是说,游戏的这种特性使得深度强化学习可以几乎无成本的获取到大量样本,以进行训练提升效果。
基于上述原因,我们认为基于深度强化学习技术优化游戏研发流程是一个很有前景的方案,在游戏研发的一些场景中进行了尝试,并取得了一定成果。在真实的商业游戏中,我们会有其他更多的需求,比如成本要足够低,Bot的行为要足够拟人,训练速度要足够快以适应游戏开发和更新的进度等,这些都是实际应用中更需关注的问题,我们也将在后续的文章中再仔细阐述。
本文中我们将先对深度强化学习的基础知识进行回顾,之后再对其在游戏中可能的几个应用场景和应用方法进行介绍。
二. 什么是深度强化学习
2.1强化学习基本概念
机器学习研究的是如何通过数据或者以往的经验来提高计算机算法的性能指标,使系统能够在下一次完成同样或者类似的任务时更加高效。根据反馈信号的不同,通常可以将机器学习分为监督学习,半监督学习,无监督学习和强化学习。其中,强化学习的训练如图3所示,其没有现成的样本,而是智能体在与环境的交互中收集相应的(状态,动作,奖赏)的样本进行试错学习,从而不断地改善自身策略来获取最大的累积奖赏。
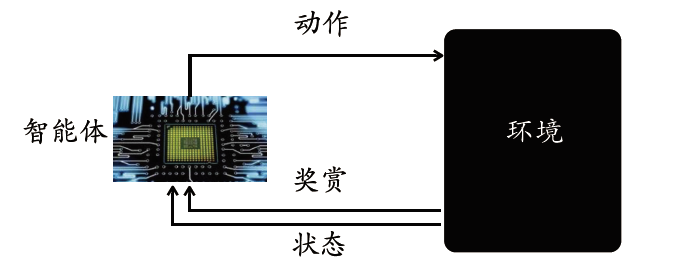
图3 强化学习典型框架
强化学习通常采用马尔科夫决策过程(Markov Decision Process, MDP) 来作为数学模型。一个MDP通常可形式化为一个五元组(S, A, T, R, ),其中S表示的是状态的集合,A表示的是动作集合,T表示是在当前状态下执行某动作转移到某个状态的概率,则表示对应的奖赏,表示折损系数。通常,我们用![]() 来表示策略,即
来表示策略,即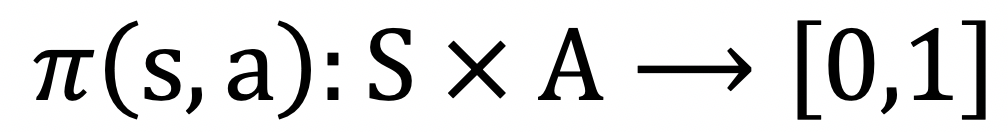 表示在状态s 下执行动作a 时的概率。
表示在状态s 下执行动作a 时的概率。
强化学习的目标就是去找到一个策略能使得累积奖赏最大,我们用() 表示从初始状态开始的累计折损奖赏: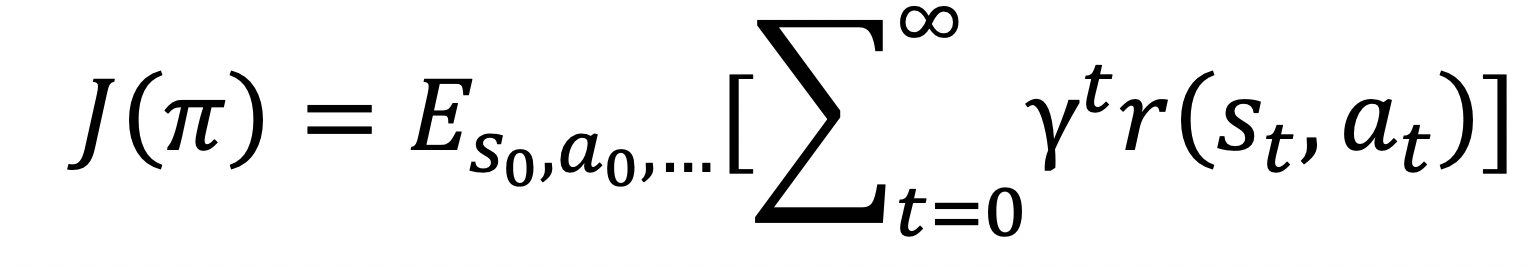 ,
,
同时,我们定义状态值函数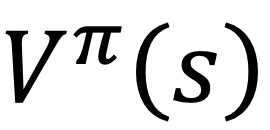 ,其表示的是从状态s开始,在策略π下获得的累积奖赏,该值函数只取决于状态s:
,其表示的是从状态s开始,在策略π下获得的累积奖赏,该值函数只取决于状态s: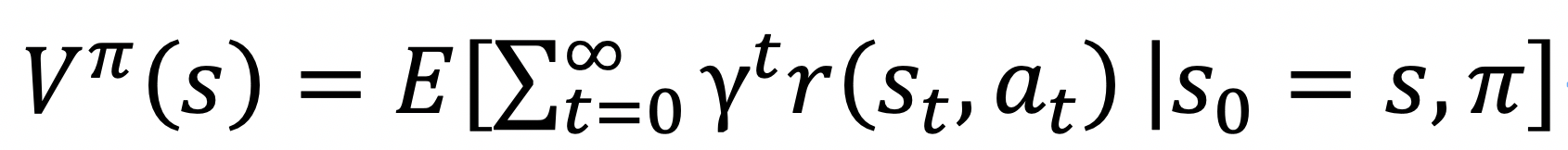 ,而状态动作值函数
,而状态动作值函数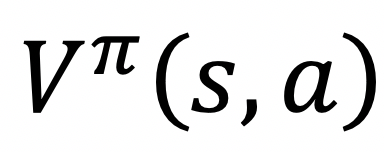 则被定义为:
则被定义为: ,显然,其表示的是从状态s,动作a开始,在策略π下获得的累积奖赏。
,显然,其表示的是从状态s,动作a开始,在策略π下获得的累积奖赏。
2.2基于值函数的方法
显然,如果我们知道每一个状态动作对对应的值函数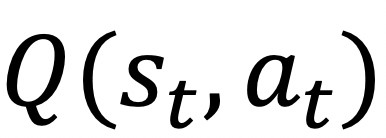 ,我们就能在每一个状态下选择值函数最大的动作,也就自然得到相应的最优策略。也就是说,可以通过求解值函数来获取最优策略,这类方法也称为基于值函数的方法。
,我们就能在每一个状态下选择值函数最大的动作,也就自然得到相应的最优策略。也就是说,可以通过求解值函数来获取最优策略,这类方法也称为基于值函数的方法。
Q-Learning是此类方法中最广泛使用的方法之一,采用时序差分的方式对Q值进行更新。首先初始化起始状态和Q值,然后每一次, 智能体在当前状态s执行动作a并收获奖赏r,进入下一状态s',并更新Q值,一次更新过程为: ,
,
其中,![]() 表示学习率。当状态和动作空间较大甚至是连续时,我们就无法实际计算每一个状态动作对的值函数,因此需要引入监督学习中的方法,用模型来拟合值函数,即:
表示学习率。当状态和动作空间较大甚至是连续时,我们就无法实际计算每一个状态动作对的值函数,因此需要引入监督学习中的方法,用模型来拟合值函数,即: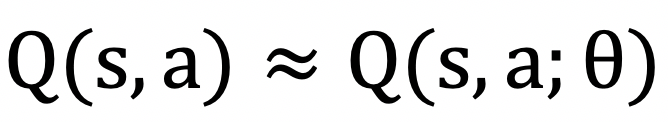 ,称之为值函数估计。
,称之为值函数估计。
当然,我们可以使用深度神经网络来进行拟合,以利用其强大的表示学习的能力,此时也就得到深度Q网络(Deep Q Network),也就是DQN,其在众多的Atari平台游戏上都取得了非常亮眼的表现。为了训练神经网络来拟合值函数,我们可以将第i轮迭代的损失函数设置为Q-learning中更新的差值的均方差,即: ,
,
然后,我们就可以利用包括梯度下降法在内的优化方法来更新网络,从而实现对值函数的估计。在此基础上,加上经验回放和目标网络两个技巧,以解决采样数据关联性太大及网络震荡的问题,DQN就可以在Atari上的很多游戏上达到甚至超过人类玩家水平,取得了当时的最好表现。
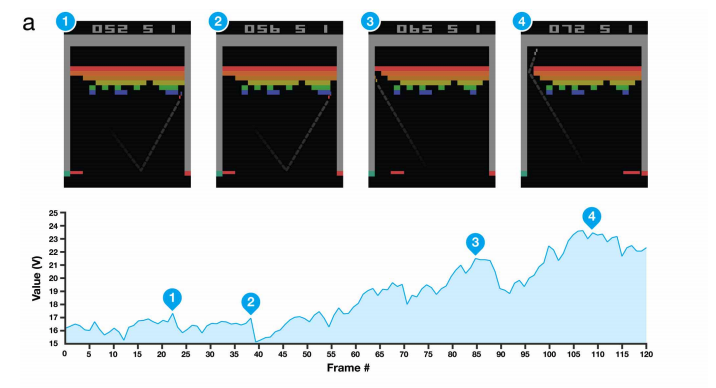
图4 用DQN算法玩Atari游戏
2.3 基于策略的方法
基于值函数的方法在很多情况下具有很好的收敛速度和收敛效果,但是却不能应对动作空间过大甚至连续的情形,以及可能出现策略退化(Policy Degradation) 的问题。基于策略的方法,也称为策略搜索,通常可以采取一个参数化的函数对策略进行表示: , 然后再寻找最优的参数w,以使得基于该策略的累计回报的期望最大,可以避免上述问题。
, 然后再寻找最优的参数w,以使得基于该策略的累计回报的期望最大,可以避免上述问题。
具体来说,在一个多步的MDP中,累积奖赏可表示为: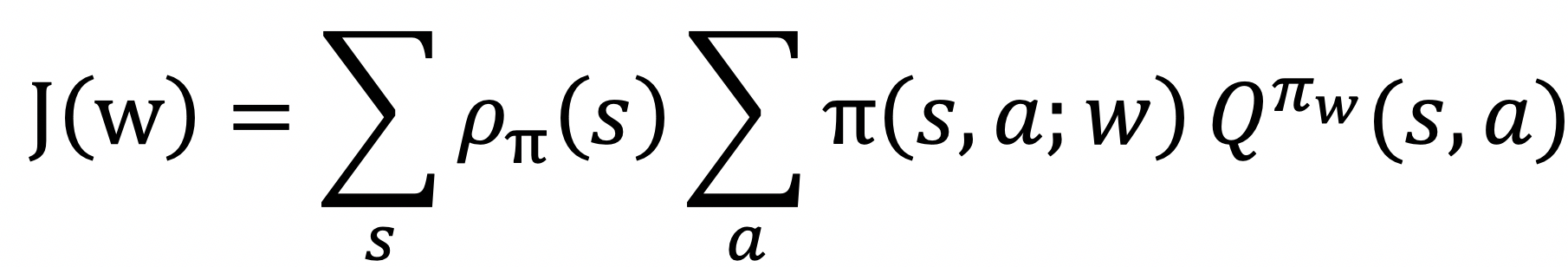 。其中,
。其中,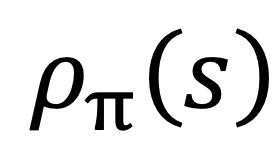 是策略π的状态密度函数,表示在策略π下出现状态s的期望。为了得到最大的累积奖赏,即求解上式的最大值,可以先计算出上式的梯度:
是策略π的状态密度函数,表示在策略π下出现状态s的期望。为了得到最大的累积奖赏,即求解上式的最大值,可以先计算出上式的梯度: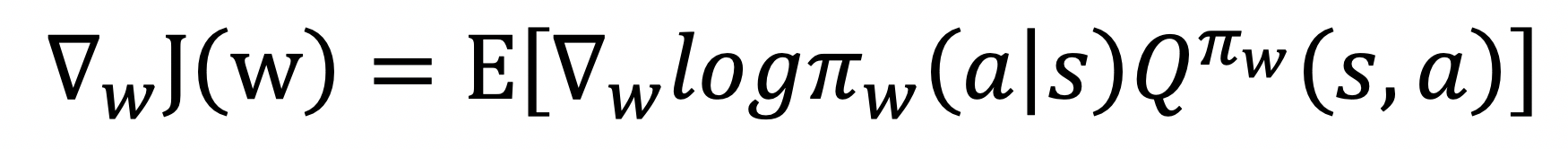 ,
,
然后就可以通过如下方式来更新参数: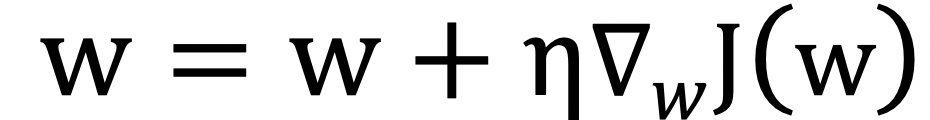 ,这就是策略梯度方法。 在此基础上,继续引入演员和批评家算法(Actor-Critic)和优势函数(AdvantageFunction)来降低方差提升学习效果,就得到了A2C算法,引入异步执行(Asynchronous)的框架提升训练效率,就得到了A3C算法。而如果将优化理论中的信赖域(Trust Region)方法引入到强化学习中,进行一定的改进,就可以得到PPO算法,其学习速度和效果都非常好,已经成为如今最为流行的强化学习算法之一。
,这就是策略梯度方法。 在此基础上,继续引入演员和批评家算法(Actor-Critic)和优势函数(AdvantageFunction)来降低方差提升学习效果,就得到了A2C算法,引入异步执行(Asynchronous)的框架提升训练效率,就得到了A3C算法。而如果将优化理论中的信赖域(Trust Region)方法引入到强化学习中,进行一定的改进,就可以得到PPO算法,其学习速度和效果都非常好,已经成为如今最为流行的强化学习算法之一。

图5 用TRPO算法控制仿真机器人的动作
三. 更聪明的Bot和NPC
3.1 游戏内的Bot和NPC
当人工智能与游戏一起出现时,相信大家首先想到的就是在游戏中会碰到的机器人(Bot)或者是非玩家角色(Non-Player Character,NPC),也就是用AI玩游戏。实际上,玩游戏确实是人工智能在游戏领域最早也最成功的应用之一。
Bot和NPC一直都在游戏中有着重要的作用。很多游戏(比如很多角色扮演类游戏)有大量的NPC,以帮助完成游戏情节,增加游戏的挑战性(比如一个很强的Boss),以及使游戏世界更加真实。而有的游戏中则需要有一些Bot来充当玩家,来帮助新手更快地学习游戏的玩法,在人数不够时能够帮助玩家完成开局,在用户离开时还能进行托管代打(很多棋牌类中游戏都有)。比如在王者荣耀中,玩家可以选择人机对战,这就是与游戏内置的Bot对战,而其中的主宰和暴君等就是NPC。
传统上业界制作游戏内Bot和NPC的方法是开发者们根据经验指定一些玩法和规则,写成行为树,从而实现控制逻辑。这种方法开发周期长,成本大,并且也很难获得非常好的表现。还有一些基于规划的方法,比如树搜索方法,基于符号表示法等,通过探索未来状态空间类决定当前应当采取的动作,这类方法在一些简单的游戏上能获得非常好的表现,而当游戏非常复杂或者无法仿真时则不再适用。另外,基于监督学习来制作游戏内AI也是可以考虑的方案,但是这种方法必须要求有大量的有标记样本,意味着只有那些已经上线,且对人类玩家的游戏内操作数据有详细记录的游戏有可能使用这种方法,且还只能应用于Bot的制作,而在其他的游戏和场景中则无法使用。
3.2 用深度强化学习研发Bot和NPC
与上述方法不同的是,深度强化学习是让智能体在环境中进行不断的探索,试错学习以最大化累积奖赏,从而得到最优策略的,也就意味着其不需要有现成的标记样本,也不用人为写规则,因此用深度强化学习来研发Bot和NPC会是一个值得考虑的方案。
在任何游戏或其他场景中应用强化学习,首先要做的就是将场景抽象为一个MDP。如图6所示,我们将所要训练的Bot或NPC作为智能体,将其所面临的游戏作为环境,角色从游戏中获取其当前的状态和奖赏,并作出相应的动作。状态用来表示当前角色的特征信息,可以直接是当前游戏画面的原始信息,再经过诸如CNN等技术进行编码提取特征,也可以是通过游戏API抽取到的有语义的信息。同样地,角色的动作可以是和人类玩家一样的按键信息,也可以是直接控制更高一级的动作API。
奖赏部分,不同的奖赏意味着不同的学习目标,需要根据我们想达到的目标进行设计。在比较简单的游戏中,可以直接用一段时间的得分甚至是一局游戏的胜负来作为奖赏,而在比较复杂的游戏中,这样简单的设定则可能无法训练或者收敛速度很慢。这一部分也被称为强化学习应用中的奖赏工程(Reward Engineering),在我们前面的一篇文章中也已经对这部分进行过详细的介绍。

图6 游戏场景形式化为MDP
在将游戏抽象为一个MDP后,我们就可以选择相应的强化学习算法进行训练,比如DQN算法,PPO算法等。与其他的机器学习方法类似,这些算法里面的超参数,网络结构,乃至学习算法等都会影响到学习效果,需要根据训练效果进行调整,以及奖赏的部分也需要根据效果进行重新的优化设计。
3.3 QQ飞车手游中的应用
QQ飞车手游是一款赛车类的手游,玩家需要综合应用包括氮气加速在内的一系列技巧来提高驾驶速度,尽快到达终点。利用深度强化学习技术,我们为QQ飞车手游制作了Bot AI,并且已经灰度上线,我们对此进行简单介绍。
如前面所说,为了应用深度强化学习,我们首先要定义好MDP。状态部分,我们选择通过游戏的API来获取包括当前赛车的速度,角度,到两侧墙壁距离,到障碍物的距离等在内的一系列信息,拼成向量,以此来表征赛车当前的状况。动作部分,我们同样利用游戏API,将左转,右转,漂移,小喷,大喷等控制进行排列组合,得到我们的动作。奖赏部分,一个简单版本的设计是:
以一段路程内花费的时间的倒数作为正奖赏,即鼓励驾驶的更快,以发生了碰撞,方向错误等负面事件为负奖赏,则一段路程对应的奖赏函数为: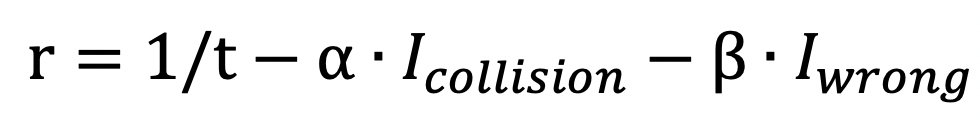 其中,
其中,![]() 和
和![]() 表示不同的加权系数,
表示不同的加权系数,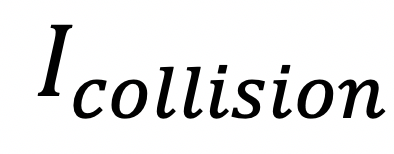 和
和 则分别表示在一段路程中是否发生了碰撞及方向错误。
则分别表示在一段路程中是否发生了碰撞及方向错误。

图7 深度强化学习训练的QQ飞车AI
在将游戏场景形式化为一个MDP后,我们选择使用PPO算法来训练模型,其具有收敛速度快,效果好的特点。经过参数上的一定调整,训练得到的模型就已能够自己驾驶车辆,并取得不错的成绩,图7就是经过深度强化学习训练得到的飞车AI。当然,上面所说的仍然只是一个非常基础的版本,还存在着很多其他的问题需要解决,比如如何能训练的足够快以应对游戏新版本上线的时间安排,比如游戏里存在着多个地图,如何能让模型在多个地图中有泛化性,比如当模型有一些奇怪的动作时如何消除,比如如何让模型具有不同级别的能力,覆盖从入门水平到顶级水平,以适用于多种场景。为了解决这些问题,就需要在算法设计和奖赏工程上做出更多的工作。
四. 更高效的游戏角色动画
4.1 游戏中的程序化内容生成
程序内容生成(Procedural Content Generation,PCG)是游戏AI中的一个领域,指的是用于自主生成或仅用有限的人力输入生成游戏内容的方法。利用PCG技术,可以生成游戏内的关卡,地图地形,游戏内的多媒体内容等,以减少游戏开发人员和美术人员的工作量,提高效率,降低游戏制作成本。实际上,早在1973年的Maze War这款游戏中,就已经开始使用算法来生成地图。
如今,一些更先进的技术,包括神经网络,对抗生成网络等,也都被尝试引进到PCG中,以期望进一步的提高游戏生产效率。比如英伟达(Nvidia)开发的一项技术,可以基于照片主动生成游戏中的纹理和材质,以及对光线进行追踪和实时渲染;比如有不少研究人员就在超级马里奥,愤怒的小鸟等游戏中尝试自动关卡生成;又比如在腾讯游戏欢乐斗地主2018年推出的残局新玩法中,大量的斗地主残局就是通过深度学习技术自动生成的,如图8所示就是其中的一个关卡。

图8 欢乐斗地主残局
4.2 用深度强化学习生成角色动画
现代游戏中的角色往往都需要看上去栩栩如生,需要有非常流畅的有机的移动效果,也就是角色动画。为了实现这个目标,有着多种解决方法,从最早的精灵动画,刚性阶层动画到如今的蒙皮动画,呈现的效果也在一步步增强。然而,模拟人类和动物的运动仍然是一个具有挑战性的问题,目前,很少有方法可以模拟现实世界中表现出的行为的多样性。手动设计控制逻辑往往会耗费大量的精力,并且又很难适应新的场景和情形。
强化学习为运动合成提供了一种可能的思路,即智能体在反复的执行各种技能的动作中进行试错学习,以减少对人力的大量依赖。然而,如果仅仅是让智能体自由探索,可能会产生一些不会影响技能目标但却无意义的动作,例如无关的上身运动,别扭的姿势等。通过结合更真实的生物工程学模型可以使动作更加自然。但是构建高保真模型难度非常大,而且得到的动作有可能还是不自然。因此,理想的自动生成角色动画的系统应该是首先为智能体提供一组符合需求的参考动作,然后以此为依据生成符合目标以及物理逼真的行为动作。比如使用深度强化学习方法来模仿运动数据的DeepLoco和用生成对抗模仿学习(GAIL)的方法来生成动作的尝试都取得了不错的效果。
来自伯克利的研究人员们则继续改进,提出了模拟效果更好的DeepMimic。同样地,首先需要根据要训练的场景定义好相应的状态和动作空间,而奖赏部分则略有不同,引入了参考片段作为奖赏的依据。具体来说,需要给智能体一些参考的运动片段,如回旋踢或后空翻等,这些片段可以是来自人类的动作捕捉数据,也可以是手绘的动画,然后就可以将智能体的动作与这些给定的参考动作的姿势的轨迹误差折算为奖赏,就可以利用深度强化学习来训练智能体做出合理的动作序列。除此之外,为了提高训练效率和训练效果,DeepMimic中还提出了两个方法,其一称之为参考状态初始化,为了提高采样效率,在每个轨迹开始时,将智能体初始化至从参考动作随机采样的状态;其二称之为提前终止,为了提高仿真效率,将肯定不可能取得好结果的轨迹提前结束,而不是继续模拟。经过上述处理,智能体能够学会如图9所示的多种高难度的技巧。
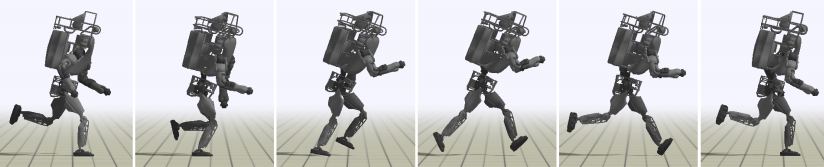
图9 DeepMimic训练得到的动作片段
在此基础上,还有一些其他的改进工作,比如参考的运动片段可以直接是从视频中得到(如YouTube上的人类动作的视频),而不一定需要来自运动捕捉,降低了成本。然而,这些工作仍然还不是直接应用在真实的商业游戏中,距离真实场景下的落地还有一段距离,比如如何控制好生成的质量达到商业要求,如何控制好生成的效率等都是需要考虑的问题。我们团队目前在利用深度强化学习生成角色动画方面也做了一些工作,并得到了一定的成果,相信马上就会有真正的产品落地。
五. 更多其他应用
用深度强化学习来玩游戏,制作游戏内的Bot或是NPC是最自然的的一个应用,具有一定的积累。而角色动画的生成也是目前学术界和游戏工业界都很关注的问题,将强化学习与一定量的参考动作结合,可以生成具有一定质量的动画序列,促进游戏开发的效率。除此之外,深度强化学习也能应用到游戏的智能化运维,精细化运营中。
游戏内存在大量的个性化推荐的场景。很多游戏中,都会存在商城以提供购买道具等增值服务,比如在商城中就可以购买武器,服饰等道具。而游戏阶段的不同,打法风格的不同,以及玩家购买力的不同都会导致玩家对游戏内道具的需求和偏好有所不同,因此道具内的推荐是需要的。游戏在推广过程中,可以通过朋友圈广告,微信游戏,QQ游戏,QQ游戏大厅、WeGame平台等多种方式来触达用户,这也意味着需要给用户合适的推荐,才能提升用户体验,增加转化率。
实际上,推荐系统是在学术界和工业界都有一定研究历史和积累的领域,如今已在电商,广告,资讯,音乐等多个行业内落地应用。这些系统中可能会应用到的算法也是种类繁多,从传统的协同过滤,关联规则到逻辑回归,树模型,从矩阵分解,知识推荐到排序学习,深度学习等方法都被使用。近年来,也有不少工作将深度强化学习方法应用于个性化推荐中,比如在淘宝的主搜场景中就有相关应用。而以应用深度强化学习来进行游戏内的道具推荐为例,此时我们的智能体就应当是推荐系统本身,而玩家及相关场景就是我们所面临的环境,状态就是由玩家的特征,最近的游戏内信息,道具信息等组成,动作就是系统所能采取的推荐决策,奖赏函数同样需要根据我们的目标进行设计。经过上述处理,使用一定的强化学习算法,我们就可以为用户进行道具的推荐了。

图10 腾讯知几人工智能伴侣
除此之外,游戏中存在着其他广泛的场景。有些游戏中存在智能对话机器人,能够在游戏过程中与玩家进行互动,解答玩家疑问,比如腾讯推出的知几人工智能伴侣。而实际上,现在有不少工作正是应用深度强化学习来进行对话系统的训练,并在多轮对话的场景下取得了不错的效果。另外,游戏的研发历程中,往往需要经过多轮测试才能正式上线,而如果在复杂游戏中用纯人工的方式进行测试,则费时费力,代价很大,一些现有的自动化工具也仍然存在很多问题。一种自然的方式是利用深度强化学习的方法来训练出一个游戏内机器人,并调整相关目标和参数,使得此机器人在游戏的场景下进行各种探索和尝试,以触发相关异常,从而对游戏进行测试。
总结
深度强化学习作为近年来火热的研究方向之一,由于在围棋和其他电子游戏上的出色表现而受到广泛关注。我们主要关注在游戏产业中如何利用深度强化学习技术,提升效率,改变生产方式。
很多游戏中都会有NPC和Bot,传统的研发方法是开发者基于一定的规则来写行为树,即人为规定好在某些情况下做出某些动作。由于游戏世界内的情况非常复杂,这种方法往往非常难实现,开发成本高,且很难达到较高的水平,也造成了玩家体验的下降。而深度强化学习技术则是通过让智能体在游戏世界内探索的方式来训练模型提升水平,在合适的设计的基础上,往往能得到比较高水平的模型。
角色动画是游戏研发过程中很重要的一项工作,在复杂的场景中,角色可能会出现非常多的行为,为每一种动作去设计和实现相应动作序列是非常繁复的动作,因此有一些工作在探索利用深度强化学习让智能体探索环境,在给出少量参考动画下训练出相应各种动作对应的动画序列。除此之外,深度强化学习也可能用于游戏的精细化运营,游戏测试以及游戏内对话机器人等场景中。
当然,我们列举的只是深度强化学习在游戏产业里较为直接的几个典型应用,其中有的已经取得了实质性的落地,为产业带来价值,有的仍然处于探索试验的阶段。其实游戏产业内有很多复杂的分工,存在着远远不止于此的繁杂多样的场景,包括深度强化学习在内的人工智能的技术也有着更多的落地的可能性等待着被挖掘。
参考资料
Sutton, Richard S. et al. Reinforcement learning: An introduction. MIT press, 2018.
Mnih, Volodymyr, et al. Human-level control through deep reinforcement learning. Nature 518.7540 (2015): 529.
Silver, David, et al. Mastering the game of Go with deep neural networks and tree search. nature 529.7587 (2016): 484.
Yannakakis, Georgios N. et al. Artificial intelligence and games. Vol. 2. New York: Springer, 2018.
Schulman, J., Levine, S., Abbeel, P., Jordan, M., & Moritz, P. (2015, June). Trust region policy optimization. In International conference on machine learning (pp. 1889-1897).
Peng, Xue Bin, et al. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Transactions on Graphics (TOG) 37.4 (2018): 143.
Peng, Xue Bin, et al. Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning. ACM Transactions on Graphics (TOG) 36.4 (2017): 41.
Shi-Yong Chen, Yang Yu, Qing Da, Jun Tan, Hai-Kuan Huang and Hai-Hong Tang. Stabilizing reinforcement learning in dynamic environment with application to online recommendation. In: Proceedings of the 24th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'18) (Research Track), London, UK, 2018.
Yang Yu, Shi-Yong Chen, Qing Da, Zhi-Hua Zhou. Reusable reinforcement learning via shallow trails. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(6): 2204-2215.
Jing-Cheng Shi, Yang Yu, Qing Da, Shi-Yong Chen, An-Xiang Zeng. Virtual-Taobao: Virtualizing real-world online retail environment for reinforcement learning. In: Proceedings of the 33nd AAAI Conference on Artificial Intelligence (AAAI’19), Honolulu, Hawaii, 2019.
2018中国游戏产业报告



