



1974年,一个名叫史蒂夫·乔布斯的年轻人来到了雅达利(Atari)公司位于洛思加图斯的总部,拿着一块他朋友沃兹尼亚克做的电路板,手舞足蹈的比划,试图让对方相信这个自制版的雅达利经典之作Pong是他做出来的,如果不给他一份工作就不会离开,后面他顺利的加入了这家当时硅谷最酷的公司,并和沃兹尼亚克一起参与研发了一款叫《Breakout》的游戏的原型,它们和《太空侵略者(Space Invader)》、《吃豆人(Pac-Man)》等游戏一起,成为了后面雅达利推出的传奇主机 Atari 2600上的经典游戏[1]。
图1 Atari上的breakout
谁能想到,仅仅十年后,1984年,电子游戏业的先驱雅达利,已经迅速的在一场被称为“雅达利崩溃”的游戏业大萧条中被出售,而乔布斯创办的苹果公司在通过 Apple II 确立了在个人计算机市场的领先地位之后,又推出了第一款的 Mac 电脑,凭借一体化设计和图形化用户界面设计再度轰动市场;2007年,第一款的 iPhone 的推出重新定义了智能手机,并将传统的游戏市场从游戏主机和 PC 向移动设备拓展;2011年,成为新一代青年偶像和创业者教父的 乔布斯去世,留下了一家全球市值最高的科技公司,与此同时,雅达利在多次的转卖之后彻底消失在大众的视野里。
但是几十年前那些在简陋的电路板上的天才创造很快又以一种大家没有预想到的形式回到风口浪尖上,2013,伦敦,一家叫 Deepmind 的创业公司提出了用一种叫深度强化学习的方法来模拟人类玩雅达利2600上的经典游戏,包括《Pong》、《Breakout》等等,在不依赖人类数据的前提下超越了人类玩家的水平[4]。在被 Google 收购之后,Deepmind 在2016年又推出了围棋 AI 程序 AlphaGo,接连击败人类世界冠军,在1997年国际象棋世界冠军卡斯帕罗夫输给 IBM 的深蓝之后,不到20年的时间,围棋也相继宣告失守,以 Deepmind、OpenAI 等为代表的一系列人工智能公司将21世纪初由大数据和深度学习方法引领的又一轮人工智能浪潮推向巅峰。

图2 Nature的DQN封面文章
电子游戏作为计算机产业的派生产物,在这几十年里获益于前沿技术的推动,迅速的成长为每年市场份额过千亿美金的庞大产业,而同时游戏也给计算机技术的前沿研究提供了大量的实验场景和驱动力,出现了一个良性循环的状态。
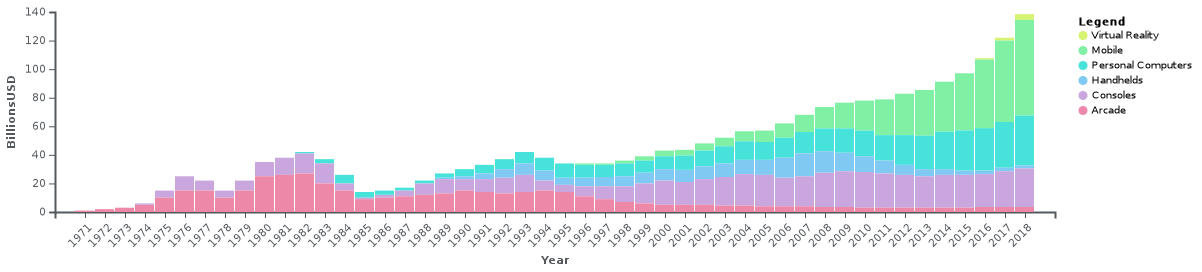
图3 电子游戏产业市场规模变化(1971-2018)
在这些技术的支持下,现在的游戏产品与比几十年前比,有更精美的画面,有更真实的音效,可以有更多天南海北互不相识的人一起玩,甚至开始有了 AR、VR 这些在人机交互方式上的创新,无一不让玩家感到惊喜。

图4 Sony 的PSVR设备
但从另外一个角度看,游戏的核心玩法似乎并没有更多的改变,主要的游戏品类,在20甚至30年前就已经出现了。新游戏的设计和玩法的创新还是高度依赖有经验的游戏研发人员,大型游戏的研发所需要承担的风险和代价越来越大,一方面来自于在玩法创新上的思路枯竭,另一方面还来自于要填充的海量内容,大量的真实 3D 场景、角色设计、剧情甚至到每一帧的角色动画的仔细打磨。毕竟,无论是主打 PVE 还是 PVP 的游戏,都需要有大量内容的填充,才能使得游戏更为充实,才能满足日益挑剔的玩家需要,在竞争激烈的市场中夺得一席之地。但是目前的人工智能技术虽然可以在星际争霸这样复杂的游戏中击败人类的职业选手,但是对游戏的玩法本身带来的帮助似乎有限,更别提创造出新的玩法或者游戏了。

图5 Atari 2600上的赛车游戏,画面简陋,但是基础玩法延续至今
但是业界在不停的尝试,试图通过人工智能技术去理解玩家在游戏中的行为,优化玩家的游戏体验以及加速游戏的研发进程,在这个系列文章里面,我们会尝试从自己的角度来阐述如何应用人工智能技术来优化游戏体验和提升游戏的研发效率,虽然很多的思路和尝试还不成熟,但是希望抛砖引玉,可以和所有有志于人工智能技术,应用新技术改进游戏研发的人一起讨论和进步。
为了可以更透彻的说明 AI 技术和游戏研发应用之间的关联和区别,下面尝试分别从 AI 研究方向和游戏研发应用两个角度来看游戏 AI 这个问题,以及解释我们的整体思路。
AI 的游戏
从人工智能研究者的视角出发,游戏是一个非常优秀的研究环境,因为游戏通常是人类世界中某一类或几类问题的抽象和简化,而且具备实验成本低(与现实世界的实验比)、可重复性高等优点,通常游戏的核心玩法都需要展现出相当程度的智能行为,无论是下围棋、打德州、组队五黑打《英雄联盟》还是自己玩连连看、俄罗斯方块,都需要有深入的思考或者敏捷的反应,从不同角度和程度上展现出人类的智能行为。因此,人工智能研究者都着眼于设计出一个可以在公认复杂的游戏中取胜的方法,这是进行创新和展示技术实力的最为直接的方式,譬如深蓝之于国际象棋,或者AlphaGo 之于围棋。
而着眼的问题也越来越复杂,从象棋到围棋,再到《Dota》或者《星际争霸》这样的实时战略游戏。

图6 AI研究的前沿从国际象棋向即时战略游戏推进
在早期的游戏 AI 相关工作中,最为常见的的方法如树搜索(Tree Search)及其变体的为主的规划类方法。在类似象棋或者围棋这样的棋类游戏中,博弈树(Game Tree)是一种常用的游戏建模形式,在博弈树上以找到最优解法为目的进行搜索就是最直接的实现 AI 的方式。但是在给定计算资源的前提下,搜索的效果总是和原始问题的复杂度成反比。从几个常见棋类游戏的复杂度上可以看到,单纯的搜索很难取得好的效果。因此搜索+极小极大算法剪枝,或者启发式的搜索,再加上强大的计算能力,在较为简单的棋类游戏上可以取得比较好的结果,譬如战胜卡斯帕罗夫的 IBM 深蓝,就是通过在针对国际象棋场景特制芯片上进行 alpha-beta 剪枝+暴力搜索实现的。
但这样的方法,在面对更为复杂的游戏,如围棋,其游戏复杂度比象棋相比是指数级的增长,完全依靠搜索不是一个理想的思路。
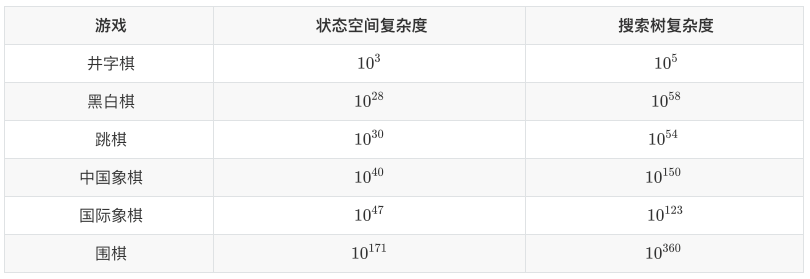
图7 不同棋类游戏的复杂度对比
20世纪90年代,当时的围棋AI第一人,曾经六夺国际围棋AI冠军的程序“手谈”的作者,中山大学陈志行教授,在半自传作品《电脑围棋小洞天》中就提到当时(2000年)围棋AI的一些局限性[2]:
-
对全局局势的判断: 受计算能力的限制,在围棋中难以基于博弈树搜索给出对当前局势的精确判断;
-
局部死活的计算方法: 局部棋的死活,也不能完全基于定式库+搜索的方法,应该多考虑一些基于直觉判断的方法作为补充;
-
如何突破定式: 象棋AI程序可以通过自身的思考(搜索)突破一些已有的定式,创造出新的合理的走法,但是围棋AI却做不到,在对战人类棋手时的缺陷非常明显。
在现在看来,以陈教授为代表的一系列围棋 AI 先行者所考虑的问题是非常有前瞻性的,纯粹以搜索+人为规则为基础的方法是没有办法解决非常复杂的问题的,陈教授在“手谈”的一个改进版本“乌鹭”中,便引入了模式识别的思想来改进对局部死活的判断,即将局部旗子的形式作为图型编码输入,把需要下一步需要关注的走位作为输出,存在模式库中,作为对纯搜索的补充。这里的模式识别的方法虽然和人工智能中模式识别(Pattern Recognition)相去甚远,但是其“凭经验直接看出关键走位/一块棋死活”的主要思想和后续基于机器学习方法在围棋 AI 上做出突破可以说是非常一致的,只是受制于当时计算机硬件和软件的发展水平,相关的思路和尝试并没有获得很好的结果。
在不到10年后,研究者将树搜索进一步拓展,引入了蒙特卡洛方法(Monte Carlo Method)和马尔可夫决策过程的概念(Markov Decision Process),提出了蒙特卡洛树搜索方法(Monte Carlo Tree Search, MCTS),基于MCTS的围棋 AI 从2008年开始战胜业余人类棋手,在2013年前后达到了可以与职业棋手在让4-5子的前提下进行对弈的水平[5]。
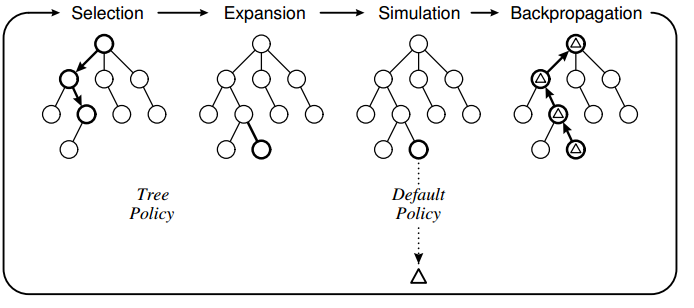
图8 MCTS的原理,基于选择、扩展、仿真和反向传递循环的树搜索
而在这10年间,得益于互联网时代的到来,不同领域的数据获取的成本都急剧的下降,海量数据成为了机器学习领域快速前进的助推剂,尤其是以深度学习为代表的复杂人工神经网络方法,在机器视觉、自然语言处理、推荐系统等领域都取得了不错的成果并形成了成熟的工业解决方案。这些可以从海量的人类标注数据中学习复杂规律的机器学习方法,正是十多年前围棋AI所梦寐以求的最后一块缺失的拼图。
2015年,Deepmind 的围棋AI程序 AlphaGo 横空出世,首次在无让子的对局中击败人类职业棋手,2016年1月,Deepmind 在 Nature 上发表相关论文“Mastering the game of Go with deep neural networks and tree search”[6],而后不久的2016年3月,AlphaGo 在五番棋比赛中以4:1击败人类世界冠军李世乭,引发了新一轮的人工智能狂潮。
在这个版本的 AlphaGo Lee 中,从历史对局中提取了3000万样本数据进行初始的监督学习(Supervised Learning)策略模型训练,使得AI可以根据一个给定的盘面判别下一步的走法,并在此之上,采用了强化学习(Reinforcement Learning)的思想对 AI 的走子能力和局面判断能力进行进一步的提升,基于这种方法强化的 MCTS 终于在面对人类职业棋手上取得了突破性进展,在不同的线下和线上比赛击败所有前来挑战人类高段职业棋手,并于2017年初以3:0再度击败人类世界冠军柯洁。
在2017年底,进化版的 AlphaGo Zero 在不依赖任何人类数据的情况下,依赖深度强化学习和自我对弈的方法,21天训练超越之前所有版本的 AlphaGo 程序,彻底明确了 AI 在围棋领域的霸主地位[7]。

图9 Nature的AlphaGo封面文章
同时,深度强化学习继续在更多的游戏场景上取得突破,从《Dota2》的 OpenAI Five 到《星际争霸2》的 AlphaStar,都取得了媲美职业玩家的表现。不依赖人类标注数据,在虚拟环境中自我探索进行学习达到并超过顶级人类选手的表现,使得深度强化学习方法成为人工智能研究最为火热的前沿,并被视为通往通用人工智能(Artificial General Intelligence)的一条可能的道路。
另外一个重要的方向,是与博弈论(Game Theory)有关的,在诸如德州扑克、麻将、斗地主等许多牌类游戏中,一局的信息并不是对决策者完全可见的,在 AI 进行计算的时候,需要对对手的状态和策略进行某种程度的猜测,这使得问题的复杂度进一步提高了,也没有办法直接用树搜索的办法来处理。
博弈论方法的引入,为在不确定性问题的处理上提供了理想的技术工具,譬如基于反事实遗憾最小化(Counter Factual Regret Minimization)方法实现的德州AI,通过寻找博弈中的纳什均衡点,在1对1,以及最近在多人德州扑克游戏上击败了人类职业玩家。同时,博弈论和多智能体(Multi-agent)相结合,在如同机器人足球,线上多人游戏的场景中,探索不同智能体间合作和对抗的策略,也给 AI 的研究方向带来了许多创新的想法,而且对于解决现实世界中的问题都是非常必要的,因为真实环境中AI面对的绝大多数问题,都是信息不完全而且存在多方合作或对抗的情况。

图10 Google Brain开源的Google Research Football研究环境
从上述的历程,我们可以看到,针对游戏相关的研究一直处于人工智能研究的最前沿,从基于规则、暴力搜索走向基于数据驱动的机器学习方法,从依赖人类历史数据走向人类设定规则、自我探索,从个体走向群体,从抽象走向真实,在这个过程中,游戏作为人类世界的简化和抽象,给 AI 研究提供了环境和方向,并激励 AI 研究者探索新的未知。在 AI 技术发展如日中天的现在,作为游戏从业者,是不是应该从另外一个角度考虑,这些 AI 技术,又给游戏自身的发展,带来了什么呢?
游戏的未来
从雅达利上的Pong开始,AI就一直是游戏中的重要组成部分,充当玩家的虚拟对手、探险路上提供食宿的村民、鼠标一点指挥千军万马井然有序奔向敌军、又或者是一花一草栩栩如生的虚拟世界,游戏世界中的许多惊喜,背后都有AI技术的支持,而正是这些技术的存在,使得游戏变的更有趣或者体验更顺畅。
《AI for Game Developers》是针对游戏研发者的游戏 AI 介绍经典教材[8],这本出版于2004年的书从在不同环境中的移动、追逐、闪避等实际场景出发,介绍了许多实际游戏 AI 开发的技巧,但是书的前半主体部分介绍的都是“确定性”的,依赖于规则或者状态机的AI实现方法,最后的部分才略微对贝叶斯方法、神经网络和遗传算法这些“非确定性”的方法有了一些介绍,而且作者也在书中提到,虽然这些“非确定性”的方法可以给游戏的可玩性和自由度上带来更多的空间,但是游戏业者在成书的年代(2004年)对这些方法保持距离的原因包括:难以理解,难以控制和测试、开发资源有限等,但是作者相信情况正在好转,游戏业者在未来会更多的接受这些“非确定性”的方法。
15年过去了,现在的情况,真的有所好转么?
目前市面上无论主机、手机、单机还是网游,绝大多数的商业化游戏产品里面所使用的AI游戏技术,依然如同15年前一样,以规则驱动、状态机等确定性的方法为主,原因是什么呢?是业界保守还是这些先进的 AI 技术有问题?
2018年有一本介绍游戏 AI 的教科书《Artificial Intelligence and Games》 (知乎专栏读书笔记系列文章分享[3]),作者就提出了一个有趣的观点:目前的游戏产品的设计源自于人工智能技术还不是非常发达的时代,导致游戏设计时候对强人工智能的依赖度不大,如果希望有一个人工智能技术扮演主要角色的游戏产品,最好从头开始围绕着人工智能技术出发进行重新的设计[9]。这个观点有一定合理的地方,AI 技术和游戏研发的磨合的确经历了漫长而痛苦的过程,但是其实经过这么多年的发展,一个变革时代已经悄悄来临,从我们的角度出发,认为有两个角度是值得关注的:
-
游戏研发效果和效率的提升
-
游戏创新的未来
先说第一点,游戏研发效果和效率的提升。电子游戏经过几十年的发展,在游戏玩法和表现形式上极大丰富,再也不是一群小伙伴挤在红白机边上看着简陋的画面玩的热火朝天的年代了,无论是单机游戏还是网游,都需要大量的内容去填充游戏世界。这里的内容,包括了游戏剧情、人物行为、玩法设计、静态场景、动画生成等等,而且每个部分都相互关联,只有更丰富更精细的内容才能让游戏产品更吸引玩家,而对于游戏研发者而言,这就意味着需要更多的人力。

图11 《荒野大镖客:救赎2》的逼真游戏环境
Rockstar 在2018年底发布的《荒野大镖客:救赎2》是年度最为热门的游戏,游戏发布半年内卖出将近2400万份,多家游戏媒体都给出满分评分,可谓市场口碑双赢之作。但是在同时,一篇揭示 Rockstar 加班文化的文章"Inside Rockstar Games' Culture Of Crunch"[10]也在网上引起热议,文章开篇就举了一个例子,在游戏开发的最后一年,公司的高层决定要在过场动画上下加入黑边,来模拟老式电影画面的风格,以求更好的符合游戏西部牛仔风格的主题。相信所有体验过游戏的玩家都觉得这是一个绝妙的创意,但是一个这样的需求,会导致游戏研发人员的工时大幅增加,为了保证添加黑边之后,动画镜头依然是对准了正确的地方,所有做好的动画都要重做。
类似这样的事情,无论是《荒野大镖客:救赎2》项目组、Rockstar,还是在其它千千万万的游戏公司,都反复的发生,所有的游戏研发人员,为了构建出一个更完美的产品,不断的推翻重来,在反复的争吵、妥协和焦虑中努力推动进度向前,许多从业者甚至认为,在现有的研发机制下,这种加班文化是游戏研发的必要之恶,是创造出艺术品一般游戏的必经之路。
如同前面提到的,为了在游戏内填充大量的内容,需要大量有经验的游戏研发研发人员,无论是游戏的策划、程序还是美术,这种对人力的强烈依赖,都导致了游戏业这种加班文化的出现。而如何将人类的经验积累并实现自动化,这正是人工智能技术的拿手好戏。因此,我们认为,通过AI技术,实现游戏研发效果和效率的提升,并不是一件不可能的任务,尤其是在游戏的智能体控制和程序化内容生成两个方面,已经有了一些较为成熟的尝试。
智能体控制,指的是游戏中的玩家和非玩家角色的控制,这里的角色控制,广义上包括角色的剧本、台词等,而狭义则指角色的游戏行为(gameplay),传统游戏AI的做法是通过规则驱动的思路来实现,即设计出角色在不同情况下的行为逻辑,再通过角色控制的接口,配合动画实现具体角色行为。
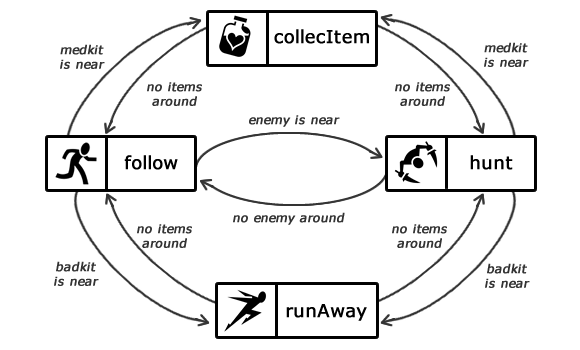
图12 基于状态机实现的NPC AI
随着游戏的复杂程度不同,这种规则驱动的方式,从简单的条件判断到状态机,再到有复杂层次结构和控制逻辑的行为树,已经能在游戏内呈现丰富的角色行为,但是基于规则的方法毕竟有其局限性,和手谈在20多年前面临的困境一样,如何突破规则的限制?如何创造出合理的行为?以机器学习为代表的人工智能技术,毫无疑问的可以做到这一点,无论是基于玩家的数据还是自我探索,数据驱动的方法肯定能产生出更创新更高强的行为模式,这一点,已经在 AI 研究者的探索中得到了充分的验证。
在我们的角度出发,首先是要解决不同类型游戏产品对应的建模问题,由于不同游戏的玩法迥异,其对应的建模形式也会有所差异,如同前述研究中采用不同领域的方法结合机器学习对问题进行建模,在有大量玩家数据的环境下选用监督学习,在缺乏玩家数据的环境下选用强化学习,利用博弈论方法处理信息不完全或者智能体间对抗的问题等等。其次,要在已经非常成熟的游戏业立足,一定需要与传统的开发流程和工具进行比较,因此需要考虑新 AI 技术的性价比、可解释性和可控制性。
非常不幸的是,这正是目前一些 AI 方法的短处,由于模型本身的复杂程度较高,导致了其难于调整和控制,相应的开发和测试成本也会比较高,因此除了算法的选择和优化,我们还需要考虑更多的工程问题,如大规模分布式训练、模型能力评估、自动化调参、模型压缩和推理优化等。
程序化内容生成,是游戏开发中非常常见的部分,指的是通过程序来自动化生成游戏的内容(关卡、美术资源等)。一个比较常见的例子就是以暗黑破坏神为代表的基于龙与地下城规则演变出的动作RPG游戏,为了提高游戏的可玩性和重玩度,这类游戏一般都包括了可以重复进行探索的关卡,关卡中包含确定的和随机的迷宫、怪物和奖励,玩家为了获得稀有的奖励反复进行游戏,而每一次的游戏体验都会由于这些随机因素而产生一定的差异,提高了反复游戏的趣味性。

图 13 暗黑类游戏的迷宫生成器
但是这样的游戏设定给游戏研发者带来了沉重的工作负担,程序化内容生成正是为解决这样问题而生的,基于开发者设计的生成规则,结合一定的随机化因素,就可以自动的生成具体的游戏元素,譬如地图上怪物的分布,数量基于给定范围的一个随机分布,分布位置则在划分好的地图格子上进行局部随机,在保证合理性的同时保留了合理性。这个部分,在人类数据和机器学习方法的帮助下,我们可以有效的理解用户行为,结合随机化生成合理的关卡设计。
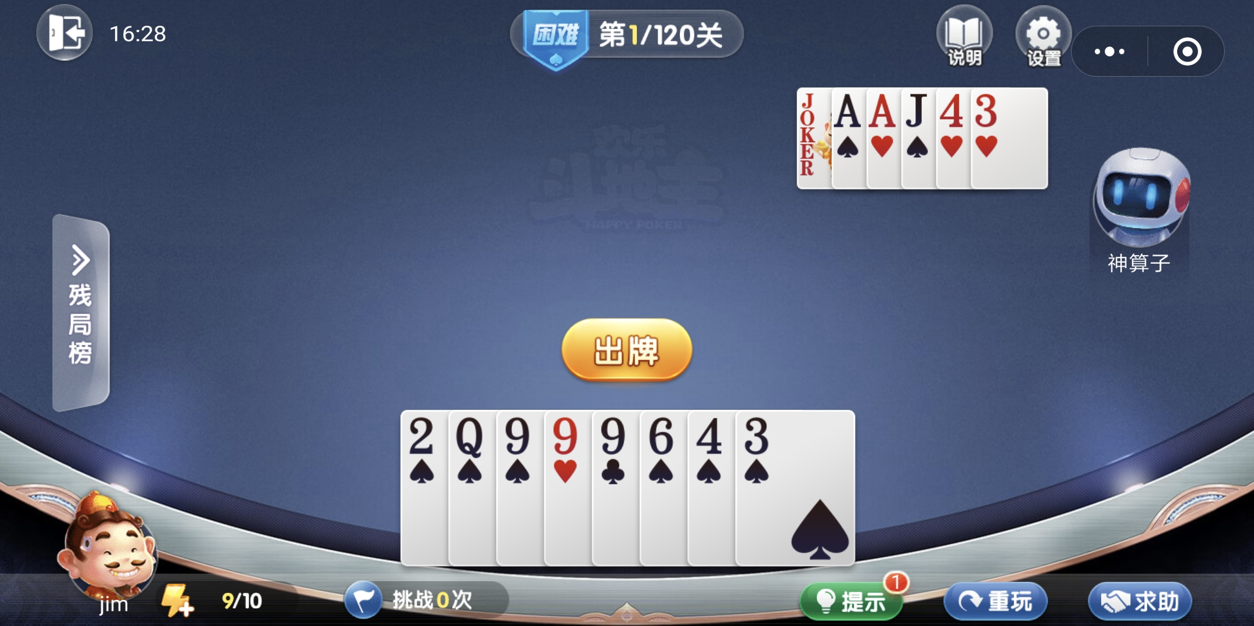
图 14 基于机器学习方法实现的斗地主残局生成器
而在美术方面,游戏美术制作需要大量人力的工作,进行原画设计、3D建模、动画设计等,同样的,从几十年前到现在,游戏美术制作工具也出现了日新月异的变化,从以往的完全依赖人力,到了可以基于工具快速生成环境、地形甚至人物形象的方法,在研究方面,近期大火的对抗生成网络(GAN)和计算机图形学的结合在这方面有非常多的应用,我们可以看到在人物建模、动画设计方面取得的一些非常有意思的进展。

图 15 工业游戏特效制作工具中的室外地形生成
除了AI技术在提升游戏研发效果和效率之外,第二点我们关注的,还是AI技术和游戏玩法,尤其是游戏设计方面的结合。但是这个部分需要更多的游戏研发人员加入到工作中来,只有从产品和技术两方面同时的思考和推动才能实现在游戏产品玩法和形态上的突破,实现通过AI技术改变游戏行业运作模式,开创更美好的未来的宏愿。
结语
接下来,关于游戏 AI 这一系列的文章会分为应用技术、平台技术两大方向分别介绍团队在最近一年多的时间里做的一些尝试和思考,中间有收获也有经验教训,有非常多不成熟的地方,但是希望通过这些文章的分享认识更多志同道合的人,一起投入到这个有挑战也有巨大机遇的工作中来。这个工作,需要学术研究界和游戏工业界两方面的同时投入,希望能够通过我们自己,还有许许多多人的努力,将游戏 AI 从 AI 间的游戏变成游戏的未来。
参考资料
1. 《乔布斯传》,沃尔特·艾萨克森,中信出版社,2011
2. 《电脑围棋小洞天》,陈志行,中山大学出版社,2000
3. 游戏人工智能 读书笔记 系列文章https://zhuanlan.zhihu.com/TGAIRC
4. Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529.
5. Coulom, Rémi. "Efficient selectivity and backup operators in Monte-Carlo tree search." International conference on computers and games. Springer, Berlin, Heidelberg, 2006.
6. Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." nature 529.7587 (2016): 484.
7. Silver, David, et al. "Mastering the game of go without human knowledge." Nature 550.7676 (2017): 354.
8. Bourg, David M., and Glenn Seemann. AI for game developers. " O'Reilly Media, Inc.", 2004.
9. Yannakakis, Georgios N., and Julian Togelius. Artificial intelligence and games. Vol. 2. New York: Springer, 2018.
10. Inside Rockstar Games' Culture Of Crunch, Jason Schreier, Kotaku, 2018



